
Diabetic Classification: A Rigorous Analysis
Published:
Under Construction.
Descriptiopn
Contents
- Dataset
- Codes
- Mount google drive
- Required libraries and libraries
- Load Data Function
- Algorithm Function
- Show Result Function
- Run the program
- Download Code
Dataset
Demo
| No. | Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 2 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 3 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 4 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 5 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| 6 | 5 | 116 | 74 | 0 | 0 | 25.6 | 0.201 | 30 | 0 |
| 7 | 3 | 78 | 50 | 32 | 88 | 31 | 0.248 | 26 | 1 |
| 8 | 10 | 115 | 0 | 0 | 0 | 35.3 | 0.134 | 29 | 0 |
| 9 | 2 | 197 | 70 | 45 | 543 | 30.5 | 0.158 | 53 | 1 |
| 10 | 8 | 125 | 96 | 0 | 0 | 0 | 0.232 | 54 | 1 |
| … | … | … | … | … | … | … | … | … | … |
Mount google drive
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
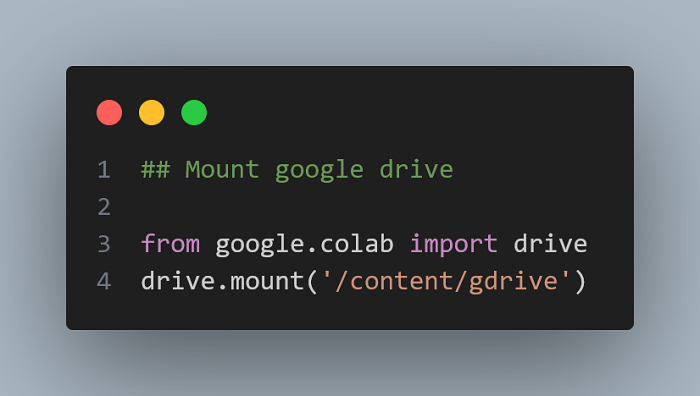
Copy the code:
from google.colab import drive
drive.mount('/content/gdrive')
Required libraries and libraries
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
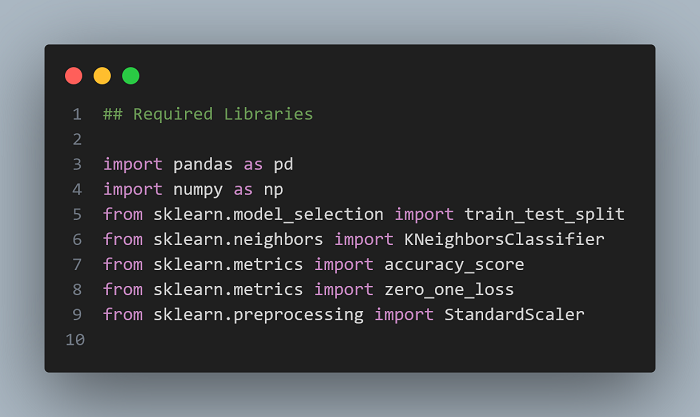
Copy the code:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import zero_one_loss
from sklearn.preprocessing import StandardScaler
Load Data Function
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
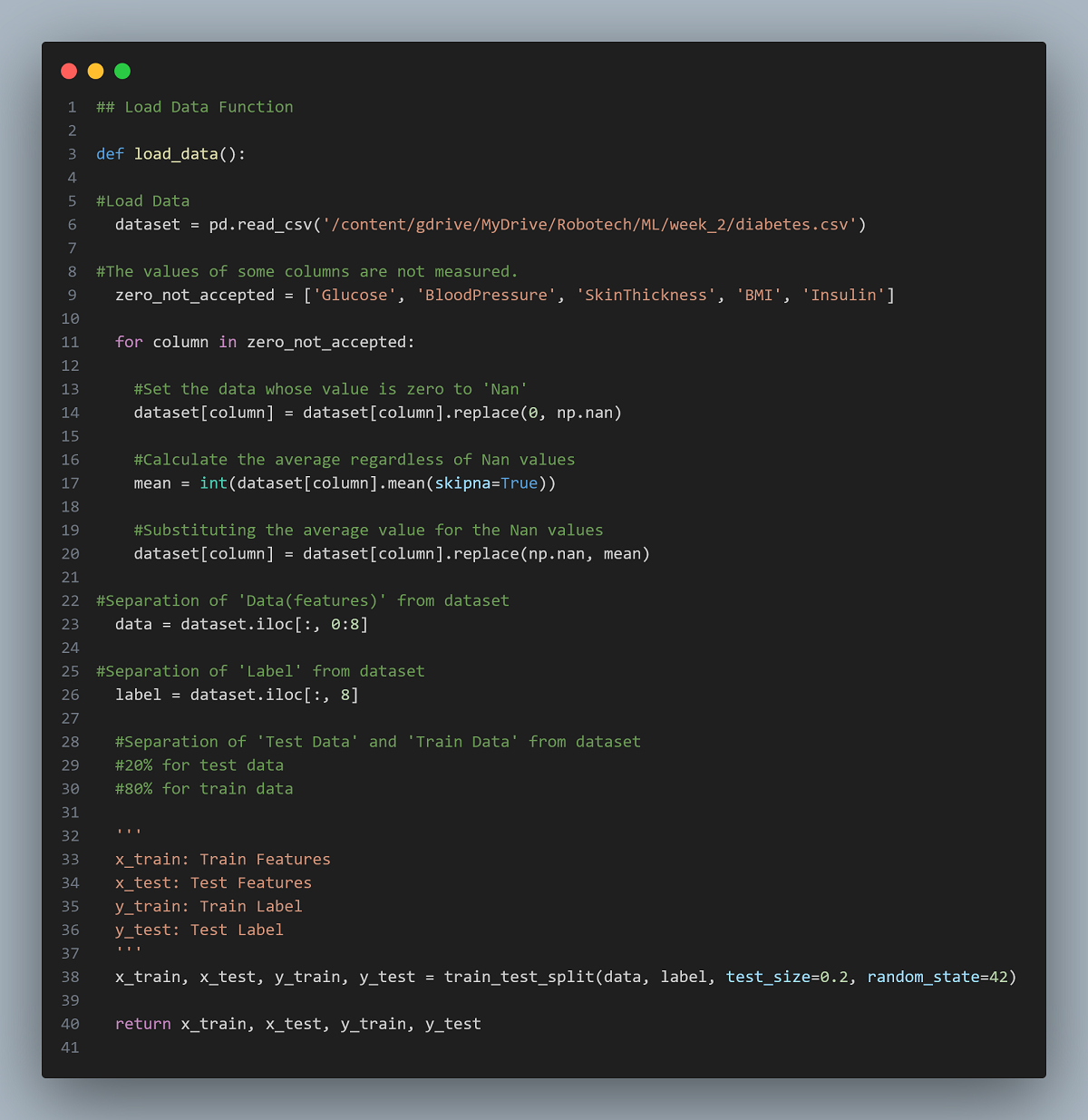
Copy the code:
def load_data():
#Load Data
dataset = pd.read_csv('/content/gdrive/MyDrive/Robotech/ML/week_2/diabetes.csv')
#The values of some columns are not measured.
zero_not_accepted = ['Glucose', 'BloodPressure', 'SkinThickness', 'BMI', 'Insulin']
for column in zero_not_accepted:
#Set the data whose value is zero to 'Nan'
dataset[column] = dataset[column].replace(0, np.nan)
#Calculate the average regardless of Nan values
mean = int(dataset[column].mean(skipna=True))
#Substituting the average value for the Nan values
dataset[column] = dataset[column].replace(np.nan, mean)
#Separation of 'Data(features)' from dataset
data = dataset.iloc[:, 0:8]
#Separation of 'Label' from dataset
label = dataset.iloc[:, 8]
#Separation of 'Test Data' and 'Train Data' from dataset
#20% for test data
#80% for train data
'''
x_train: Train Features
x_test: Test Features
y_train: Train Label
y_test: Test Label
'''
x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.2, random_state=42)
return x_train, x_test, y_train, y_test
Algorithm Function
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
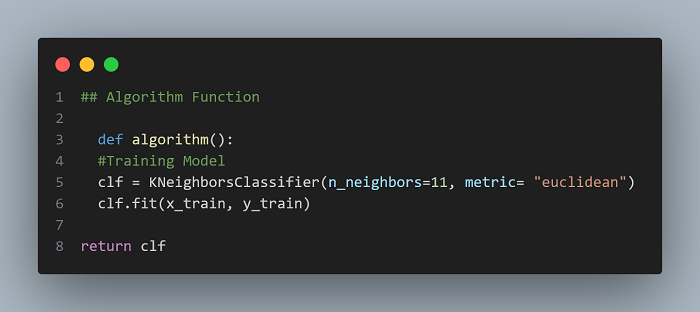
Copy the code:
def algorithm():
#Training Model
clf = KNeighborsClassifier(n_neighbors=11, metric= "euclidean")
clf.fit(x_train, y_train)
return clf
Show Result Function
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
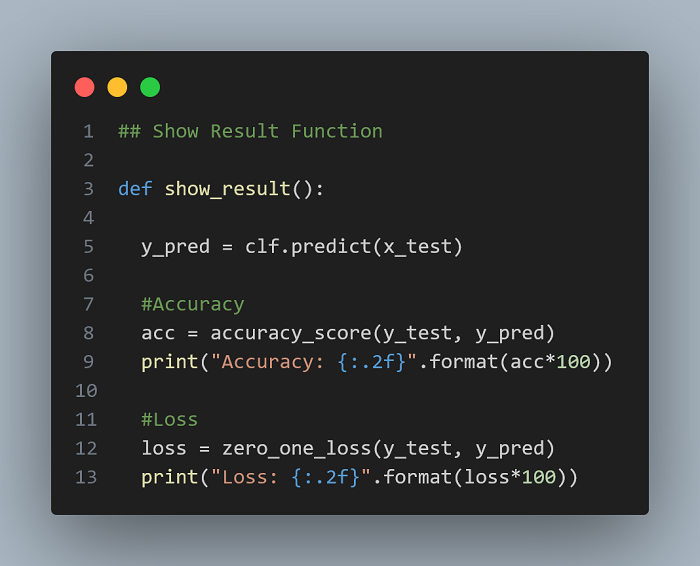
Copy the code:
def show_result():
y_pred = clf.predict(x_test)
#Accuracy
acc = accuracy_score(y_test, y_pred)
print("Accuracy: {:.2f}".format(acc*100))
#Loss
loss = zero_one_loss(y_test, y_pred)
print("Loss: {:.2f}".format(loss*100))
Run the program
I Lorem ipsum is a placeholder text commonly used to demonstrate the visual form of a document or a typeface without relying on meaningful content.
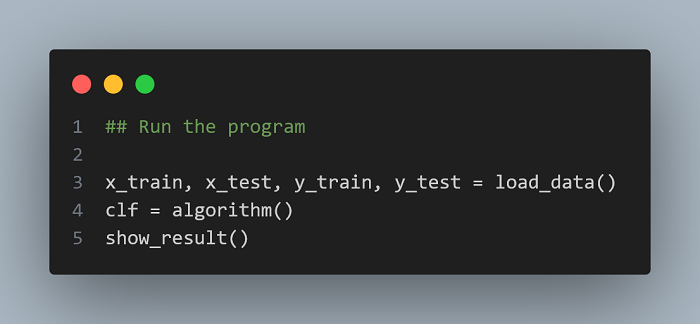
Copy the code:
x_train, x_test, y_train, y_test = load_data()
clf = algorithm()
show_result()
Code
🔸 Downlload code
🔸 Colab